Understanding LLM's
What is a Large Language Model (LLM)
A large language model (LLM) is a type of AI that can process and produce natural language text. It learns from a massive amount of text data such as books, articles, and web pages to discover patterns and rules of language from them.
How large are they?
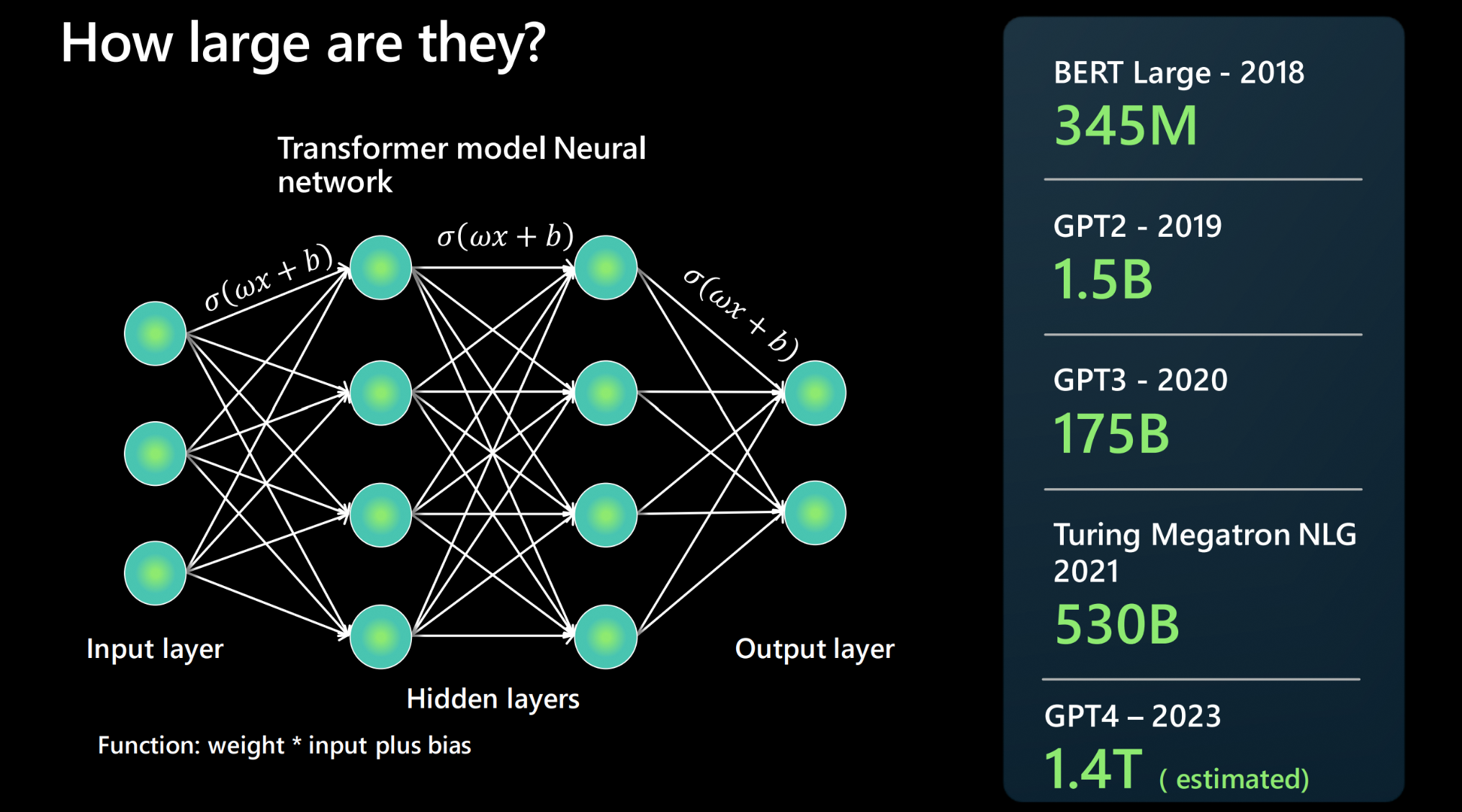
An LLM is built using a neural network architecture. It takes an input, has a number of hidden layers that break down different aspects of language, and then an output layer. People often report how the next foundational model is bigger than the last - what does this mean? The more parameters a model has, the more data it can process, learn from, and generate. For each connection between two neurons of the neural network architecture, there is a function: weight * input + bias. These produce numerical values that determine how the model processes language. They are rather large when they can report millions of parameters back in 2018 to trillions of parameters being calculated by GPT4 in 2023.
Where do 'foundational models' fit into LLMs?
A foundation model refers to a specific instance or version of an LLM, such as GPT-3, GPT-4 or Codex, that has been trained and fine-tuned on a large corpus of text or code (in the case of the Codex model). A foundational model takes in training data in all different formats and uses a transformer architecture to build a general model. From there adaptions and specializations can be created to achieve certain tasks via prompting or fine-tuning.
How does a LLM differ from more traditional natural language processing (NLP)?
| Traditional NLP | Large Language Models |
|---|---|
| One model per capability needed. | Single model for variety of natural language use cases |
| Provide the model a set of labelled data to train ML model on | Uses many TBs of unlabelled data in the foundation model |
| Highly optimized for specific use cases | Describe in natural language what you want the model to do |
What doesn't a LLM do?
- Understand language: its just a predictive engine that based on text it has seen previously will pull patterns together to produce text. Also does not understand math.
- Understand facts: there are no separate 'modes' for "information retrieval" and "creative writing", it just predicts the next most probably token.
- Understand manners, emotion or ethics: Avoid anthropomorphizing LLMs or claiming they 'understand' anything: the output is just a combination of the training data and the prompts.
Understanding tokens
We've mentioned "tokens" a few times without stopping to explain what they are. Let's do that now.
The OpenAI natural language models don't operate on words or characters as units of text, but on something in-between: tokens. A token may be a single character, or a fraction of a word, or an entire word. Many common words are represented by a single token, less common words are represented by multiple tokens.
Open AI has a useful Tokenizer website that can help you understand how it tokenizes your requests - navigate there now and try out the examples below: https://platform.openai.com/tokenizer.
When you enter text in the prompt box, a counter appears below that counts the total number of tokens in the box. (Note: the counter takes a few seconds to update if you're actively typing.)
How many tokens are in the following words?
apple
blueberries
Skarsgård
As a common word, "apple" requires only one token. The word "blueberries" requires two tokens: "blue" and "berries". Unless they are very common, proper names generally require multiple tokens. It's this token representation that allows AI models to generate words that are not in any dictionary, but without having to generate text on a letter-by-letter basis (which could easily result in gibberish).
The natural language models generate completions one token at a time, but the generated token is not deterministic. At each step, the model outputs a list of all possible tokens with associated weights. The API samples one token from this list, with heavily-weighted tokens more likely to be selected than the others.
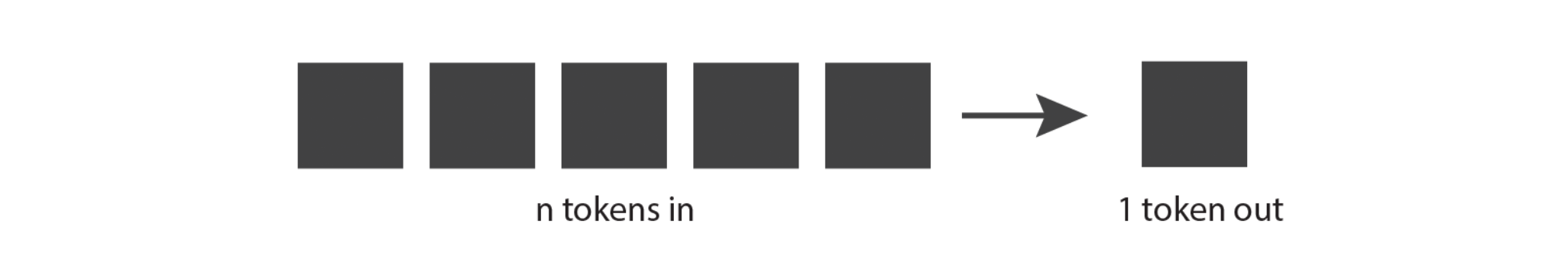
Then it adds that token to the prompt and repeats the process until the "Max length (tokens)" limit is met for the completion, or until the model generates a special token called a "stop token", which prevents further tokens from being generated. (This blog by Beatriz Stollnitz explains the process in more detail.)
This is how the model generates completions of one or more words, and why those completions can change from invocation to invocation.
Token limits
Every model has a limit on the number of tokens it can process in a single request. For gpt-35-turbo it is 4,096 tokens, and you can see the limits for other models here. Note that this limit applies to the total number of tokens in the prompt and the completion: as we've seen, the completion is added to the prompt before the next token is generated, and both must be contained within the token limit.
Newer models like gpt-4-32k have much larger token limits: up to 32,768 tokens. This not only allows for longer completions but also much larger prompts. This is particularly useful for prompt engineering, as we'll see later.
Using Generative AI
Most people are familiar with natural language generative AI from applications like ChatGPT, but you can use these models for much more than chatbots. In this section, we'll explore some other useful applications of these models.
Information extraction
The example below shows how you can combine a prompt with data to extract information using natural-language instructions. In this case, the completion extracts the name, company, location, and phone number from an email. Modify the prompt and the source data to extract different information.
Extract the person name, company name, location and phone number from the text below.
Hello. My name is Robert Smith. I’m calling from Contoso Insurance, Delaware. My colleague mentioned that you are interested in learning about our comprehensive benefits policy. Could you give me a call back at (555) 346-9322 when you get a chance so we can go over the benefits?
Extract structured data from text
In this example, we provide freeform narrative about fictitious fruits, and prompt the model to generate a table of all the fruits mentioned and their attributes.
In this example, we "primed" the model with the desired output format: a header row, and a couple of examples.
There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy. There are also loheckles, which are a grayish blue fruit and are very tart, a little bit like a lemon. Pounits are a bright green color and are more savory than sweet. There are also plenty of loopnovas which are a neon pink flavor and taste like cotton candy. Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them.
Please make a table summarizing the fruits from Goocrux
| Fruit | Color | Flavor |
| Neoskizzles | Purple | Sweet |
| Loheckles | Grayish blue | Tart |
Try extending the prompt by appending the following text:
Please also make a JSON array summarizing the fruits from Goocrux:
The model will now return a JSON array of the fruit and their attributes.
Classification
In this example, we provide one example of a headline and a category, and ask the model to classify a second example. This is an example of "one-shot learning": with just one example, the model can generalize to classify a new example.
Classify the following news headline into 1 of the following categories: Business, Tech, Politics, Sport, Entertainment
Headline 1: Donna Steffensen Is Cooking Up a New Kind of Perfection. The Internet's most beloved cooking guru has a buzzy new book and a fresh new perspective
Category: Entertainment
Headline 2: Major Retailer Announces Plans to Close Over 100 Stores
Category:
Try replacing Headline 2 with other text and regenerating the completion. Does it generate the appropriate category?
Jets lose, again!
Obama announces re-election bid
Microsoft up in after-hours trading
20nm process offers more density and better power value
Text summarization
Text summarization is a well known capability of ChatGPT - it creates a short summary of a larger piece of text. Add tl;dr (for "too long; didn't read") to gain a summary of the article below. Where can you see this being useful in your business?
At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI Cognitive Services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there’s magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better.
We believe XYZ-code will enable us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pre-trained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks.
Next steps
These examples are illustrative as one-off demonstrations, but their real power comes with automation. You can use the Azure OpenAI service to perform similar tasks either on-demand (say, as a customer request form is submitted) or in batch mode (say, to extract data points from a database of unstructured text responses). Lets move on to learn more about Prompt Engineering in the chat interface.